Even Basic AI Can Now Write News That Passes as Human
New research indicates that even small local AI models can now write news that people cannot distinguish from real journalism, matching top systems, and leaving readers unable to tell who wrote what.
According to a new research collaboration between Germany and France, humans can’t tell whether a news article is written by AI or a human – even when it’s written by open source models that can be downloaded and run on relatively average consumer-level desktop computers.
In another indication that small AI is on the ascendant, a survey of 2,318 judgements collected from 1,054 participants in a dedicated academic study portal found that human readers could not identify the provenance of an article at a higher than chance level, even when it was output by relatively modest models with as few as seven billion parameters, including Mistral and Llama variants:

Mean source and authenticity scores for LLMs tested. GPT-4o’s 200 billion parameters do not massively exceed the 7B parameters of smaller models. Those tested for the study were Gemma 7B, Phi-3 Mini, LLaMA-2 13B, Mistral 7B, GPT-4o, and GPT-3.5. Source
The authors are returning to a subject that they first examined in the 2024 release Blessing or curse? A survey on the Impact of Generative AI on Fake News. The findings themselves are newly-released results from a larger project initially announced in January, and make use of the authors’ own JudgeGPT online participatory framework.
Featherweight Power
Titled Can Humans Tell? A Dual-Axis Study of Human Perception of LLM-Generated News, and coming from three researchers across Frankfurt University of Applied Sciences and the IRISA research unit at Nantes, the new study’s methodology makes an important distinction between ‘fake news’ and ‘AI-written news’ (since fake news can be written by people, or by AI, and the two facets are not necessarily synonymous).
However, perhaps the most interesting aspect is the paper’s conclusion that small models including Mistral 7B and Gemma 7B can, with only seven billion parameters, square off with aplomb against the likes of a ChatGPT model (4o) with 200 billion parameters:
‘Open-weight models with as few as 7B parameters produce text rated no differently from GPT-4o output, indicating that the capability to generate human-indistinguishable text is no longer restricted to frontier models.’
However, ‘AI-generated news’ can represent many different kinds of human/AI collaboration, from spell-checking through to full, career-ending deferral of effort, and the study does not make clear exactly what kind of AI content was produced for the tests (though it does outline the methodology for producing it – see below).
Method
For the participants engaged with the JudgeGPT platform, each news fragment was assessed using a dual-axis framework in which they provided three independent ratings on continuous 0-100 sliders:

The JudgeGPT portal GUI, where raters assess material on source attribution; authenticity; and topic familiarity. Please refer to the source paper for better resolution.
Source judgment captured whether a passage seemed machine-written or human-written; authenticity judgment, whether it was perceived as fake or legitimate; and topic familiarity, how well the reader knew the subject.
Continuous scales were used instead of a Likert scale, to capture degrees of certainty more precisely, and to support statistical analysis, including Pearson correlation and clustering.
Machine-generated text fragments were produced by the authors’ own RogueGPT framework, the feeder architecture for JudgeGPT. RogueGPT orchestrates contributions from six Large Language Models (LLMs): ChatGPT-4; ChatGPT-3.5; ChatGPT-4o; LLaMA-2 13B; Gemma 7B; and Mistral 7B.
Persona-based prompting was used to generate the texts, and the AI generations were grounded in real news topics, and were fact-checked by humans.
Advertisement
Conversely, human-written fragments were sampled from ‘established news outlets’ and unspecified ‘information databases’.
The authors observe:
‘The stimulus set is intentionally skewed toward machine-origin fragments (∼98%), with human-origin items serving as calibration anchors.
‘This design choice reflects the study’s focus on within-AI variation (across models) rather than human-vs.-AI comparison; participants are not informed of the base rate, and the near-chance detection [results] hold when analyzed on the human-origin subset alone.’
Participants first gave informed consent and completed a demographic questionnaire covering age, education, political orientation, and familiarity with AI, after which they evaluated the sequence of news fragments.
Each person reviewed between 5-87 items, with a median of 12, while presentation-order was randomized, and model assignment balanced across participants, to reduce bias. The platform recorded the three slider ratings alongside response time and an anonymous identifier, allowing individual judgments to be linked with background factors.
The authors take pains to point out that the sample skewed toward educated European participants, with 68% university-educated, and 74% based in Europe – a bias that the paper notes as a limitation for broader generalization.
Tests
The tests are divided into five finding-types: distinguishing machine-generated from human-written text; comparing detection across different LLMs; examining the effect of domain expertise versus political orientation on accuracy; identifying distinct response strategies among participants; and tracking how accuracy changes over repeated evaluations, due to fatigue:
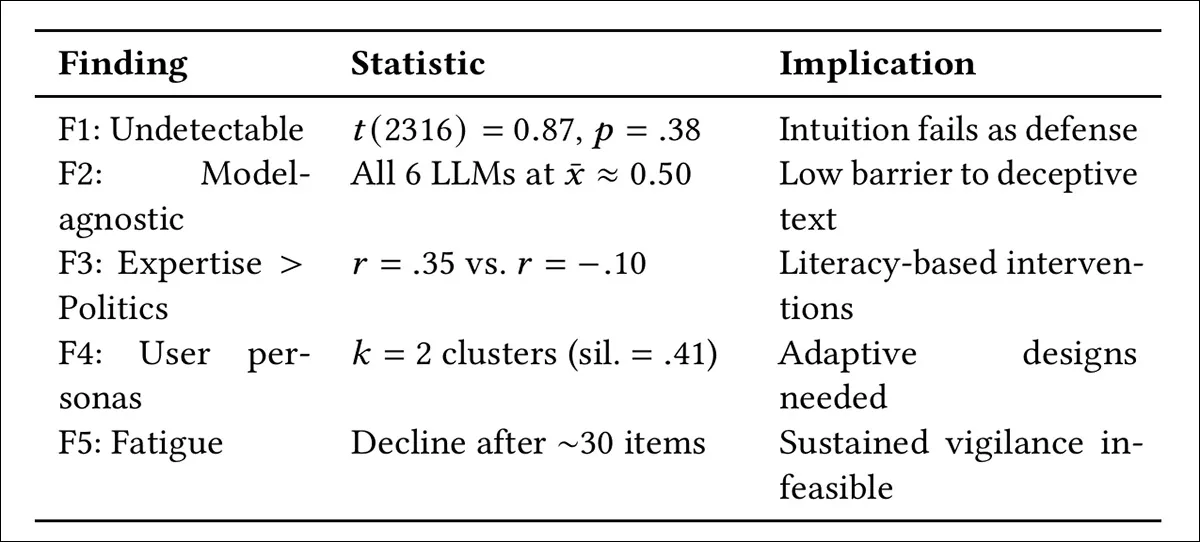
Summary of the five core findings from 2,318 judgments across 1,054 participants, showing that human detection of AI-written text remained at chance levels across all models, that accuracy was linked to domain expertise rather than political orientation, that participants clustered into distinct trust profiles, and that performance declined after roughly 30 evaluations, due to cognitive fatigue.
The test showed no significant above-chance difference in source scores between conditions, apparently indicating that participants cannot distinguish AI-generated text from human output:

Source and authenticity score distributions for machine- and human-origin fragments show substantial overlap, with no meaningful separation between the two conditions, and statistical testing –indicating that participants could not reliably distinguish AI-generated text from human-written content.
For the second aspect, as shown in the graph at the beginning of the article, detection failure did not vary by model, as outputs from all the LLMs clustered around chance-level judgments, with no significant differences between them. Even smaller open-weight systems such as Mistral 7B and Gemma 7B were rated no differently from GPT-4o, indicating that human-indistinguishable text may no longer be limited to the largest models.
For the third aspect, accuracy was more strongly linked to domain expertise than to political orientation, as familiarity with fake news correlated with better judgments, while political views showed no meaningful effect, suggesting that learned analytical skills may matter more than ideology:

Results for the third line of investigation showed that political orientation had no meaningful effect on source attribution or authenticity scoring, with only weak, non-significant trends, while self-reported familiarity with fake news was associated with higher accuracy on both axes. This suggests that experience-based analytical skill was a stronger predictor of performance than ideological position. Please refer to the source paper for better resolution.
The fourth finding showed that participants clustered into two distinct response styles identified as ‘Skeptics’ – who assigned low trust across content regardless of origin – and ‘Believers’ – who maintained a higher baseline of trust.
Finally, regarding the fifth objective, a rolling analysis of sequential judgments showed that participants initially became better at the task, with accuracy improving over roughly the first 15-20 evaluations as they adapted to the format:
Advertisement

Rolling averages of source attribution and authenticity scores across the sequence of participant evaluations show a short initial improvement phase, as users appear to adapt to the task during the first 15–20 items, followed by a steady decline in both measures after roughly 30 evaluations. Please refer to the source paper for better resolution.
However, this effect was short-lived, as performance began to decline after around 30 items, with participants increasingly defaulting to labeling content as fake – a shift interpreted as cognitive fatigue, and suggesting clear limits on how long detection-based approaches can remain effective, in practice.
This may represent some empirical evidence that, exhausted by the prospect of distinguishing fake news from real, AI news from human, we may tend to default to assuming the news is AI and/or fake (not necessarily the same thing), to be ‘on the safe side’. Those who consider this ‘lazy’, and consider that people should do their own research to verify a potential fake news story, might be interested to learn that a 2024 study indicated this only makes the problems worse.
The authors suggest that the failure of human judgment evinced in the results indicates that we may need to defer such matters to cryptographic provenance technologies such as the Adobe-led C2PA initiative. Other possible solutions mentioned are the authors’ own OriginLens framework, and another author-involved project called CRED-1.
The authors conclude:
‘Can humans tell? Our dual-axis study of 2,318 judgments across six LLM families provides a clear empirical answer: they cannot.
‘Machine-generated text is indistinguishable from human writing regardless of model size or family, domain expertise predicts detection accuracy more strongly than political orientation, participants adopt distinct trust strategies, and cognitive fatigue limits sustained detection.
‘These findings support a shift from user-level detection toward system-level countermeasures, including content provenance, adaptive trust indicators, and bounded inoculation interventions.’
Conclusion
The concerning aspect of this paper is the ambient support network of projects and papers that the authors – or some of the authors, depending on the work – have originated or else have a hand in; and it certainly would have been illuminating if one could have studied samples of AI and human-generated text that produced these results, in order to make better sense of the kind of output that the described generation methodology produces.
Nonetheless, it is intriguing to hear that open-weight, open source models can compare to API-driven behemoths such as the ChatGPT series – can it be that the task at hand is actually not that difficult, and that a 200-billion parameter model is overkill for such tasks? We would need to know a little more about the submitted AI and human-written source samples in order to answer that question.
In the meantime, according to the canirun.ai website, Mistral 7B (which was more or less on a par with ChatGPT -4o in the tests) ‘runs great’ on a NVIDIA RTX 3080 with 16GB of VRAM, and runs ‘decent’ on a 3060 with 6GB of VRAM – hardly the latest or greatest graphics cards in play*. So anyone who wants to devise their own methodology for sample submission can apparently participate in these experiments too.
Subscribe to our newsletter
Get the latest PC component price drops and tech tips delivered to your inbox weekly.